Researchers like to study samples of data and look for associations between variables. Often those associations are represented in the form of correlation coefficients, which go from -1 to 1. Another popular measure of association is the path coefficient, which usually has a narrower range of variation. What many researchers seem to forget is that the associations they find depend heavily on the sample they are looking at, and on the ranges of variation of the variables being analyzed.
A forgotten warning: Causation without correlation
Often those who conduct multivariate statistical analyses on data are unaware of certain limitations. Many times this is due to lack of familiarity with statistical tests. One warning we do see a lot though is: Correlation does not imply causation. This is, of course, absolutely true. If you take my weight from 1 to 20 years of age, and the price of gasoline in the US during that period, you will find that they are highly correlated. But common sense tells me that there is no causation whatsoever between these two variables.
So correlation does not imply causation alright, but there is another warning that is rarely seen: There can be strong causation without any correlation. Of course this can lead to even more bizarre conclusions than the “correlation does not imply causation” problem. If there is strong causation between variables B and Y, and it is not showing as a correlation, another variable A may “jump in” and “steal” that “unused correlation”; so to speak.
The chain smokers “study”
To illustrate this point, let us consider the following fictitious case, a study of “100 cities”. The study focuses on the effect of smoking and genes on lung cancer mortality. Smoking significantly increases the chances of dying from lung cancer; it is a very strong causative factor. Here are a few more details. Between 35 and 40 percent of the population are chain smokers. And there is a genotype (a set of genes), found in a small percentage of the population (around 7 percent), which is protective against lung cancer. All of those who are chain smokers die from lung cancer unless they die from other causes (e.g., accidents). Dying from other causes is a lot more common among those who have the protective genotype.
(I created this fictitious data with these associations in mind, using equations. I also added uncorrelated error into the equations, to make the data look a bit more realistic. For example, random deaths occurring early in life would reduce slightly any numeric association between chain smoking and cancer deaths in the sample of 100 cities.)
The table below shows part of the data, and gives an idea of the distribution of percentage of smokers (Smokers), percentage with the protective genotype (Pgenotype), and percentage of lung cancer deaths (MLCancer). (Click on it to enlarge. Use the "CRTL" and "+" keys to zoom in, and CRTL" and "-" to zoom out.) Each row corresponds to a city. The rest of the data, up to row 100, has a similar distribution.

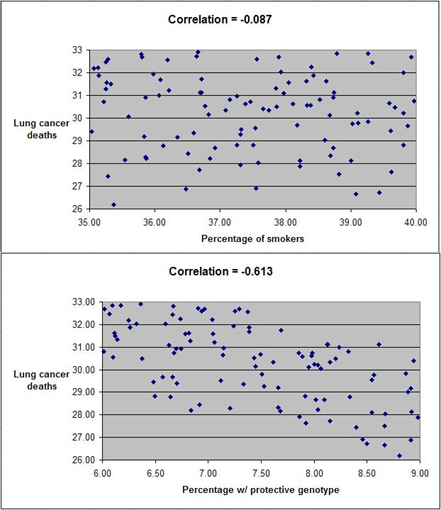
The graphs below show the distribution of lung cancer deaths against: (a) the percentage of smokers, at the top; and (b) the percentage with the protective genotype, at the bottom. Correlations are shown at the top of each graph. (They can vary from -1 to 1. The closer they are to -1 or 1, the stronger is the association, negative or positive, between the variables.) The correlation between lung cancer deaths and percentage of smokers is slightly negative and statistically insignificant (-0.087). The correlation between lung cancer deaths and percentage with the protective genotype is negative, strong, and statistically significant (-0.613).
Even though smoking significantly increases the chances of dying from lung cancer, the correlations tell us otherwise. The correlations tell us that lung cancer does not seem to cause lung cancer deaths, and that having the protective genotype seems to significantly decrease cancer deaths. Why?
If there is no variation, there is no correlation
The reason is that the “researchers” collected data only about chain smokers. That is, the variable “Smokers” includes only chain smokers. If this was not a fictitious case, focusing the study on chain smokers could be seen as a clever strategy employed by researchers funded by tobacco companies. The researchers could say something like this: “We focused our analysis on those most likely to develop lung cancer.” Or, this could have been the result of plain stupidity when designing the research project.
By restricting their study to chain smokers the researchers dramatically reduced the variability in one particular variable: the extent to which the study participants smoked. Without variation, there can be no correlation. No matter what statistical test or software is used, no significant association will be found between lung cancer deaths and percentage of smokers based on this dataset. No matter what statistical test or software is used, a significant and strong association will be found between lung cancer deaths and percentage with the protective genotype.
Of course, this could lead to a very misleading conclusion. Smoking does not cause lung cancer; the real cause is genetic.
A note about diet
Consider the analogy between smoking and consumption of a particular food, and you will probably see what this means for the analysis of observational data regarding dietary choices and disease. This applies to almost any observational study, including the
China Study. (Studies employing experimental control manipulations would presumably ensure enough variation in the variables studied.) In the China Study, data from dozens of counties were collected. One may find a significant association between consumption of food A and disease Y.
There may be a much stronger association between food B and disease Y, but that association may not show up in statistical analyses at all, simply because there is little variation in the data regarding consumption of food B. For example, all those sampled may have eaten food B; about the same amount. Or none. Or somewhere in between, within a rather small range of variation.
Statistical illiteracy, bad choices, and taxation
Statistics is a “necessary evil”. It is useful to go from small samples to large ones when we study any possible causal association. By doing so, one can find out whether an observed effect really applies to a larger percentage of the population, or is actually restricted to a small group of individuals. The problem is that we humans are very bad at inferring actual associations from simply looking at large tables with numbers. We need statistical tests for that.
However, ignorance about basic statistical phenomena, such as the one described here, can be costly. A group of people may eliminate food A from their diet based on coefficients of association resulting from what seem to be very clever analyses, replacing it with food B. The problem is that food B may be equally harmful, or even more harmful. And, that effect may not show up on statistical analyses unless they have enough variation in the consumption of food B.
Readers of this blog may wonder why we explicitly use terms like “suggests” when we refer to a relationship that is suggested by a significant coefficient of association (e.g., a linear correlation). This is why, among other reasons.
One does not have to be a mathematician to understand basic statistical concepts. And doing so can be very helpful in one’s life in general, not only in diet and lifestyle decisions. Even in simple choices, such as what to be on. We are always betting on something. For example, any investment is essentially a bet. Some outcomes are much more probable than others.
Once I had an interesting conversation with a high-level officer of a state government. I was part of a consulting team working on an information technology project. We were talking about the state lottery, which was a big source of revenue for the state, comparing it with state taxes. He told me something to this effect:
Our lottery is essentially a tax on the statistically illiterate.